
Data Loss Prevention combined with Data Classification – business benefits
GDPR, PCI DSS, NIS directive … Due to the increasing digitalization, organizations and states require new standards of user protection in cyberspace. As the restrictions connected to storing and processing of sensitive data increase, so does the interest in software for their classification and protection. Virtually every employee generates sensitive data – working with personal data (sales, HR), financial data (accounting, finance) or data constituting to a competitive advantage (price lists, projects). This data is processed in many ways: copied, cut, restructured, paraphrased, restructured…
This greatly complicates the process of data protection. It is relatively easy to protect data structured in a table or document with a known layout. On the other hand, it is far worse if it is unstructured data – non-standard contracts, memoranda or e-mail fragments.
The question is – what can we do with the data in terms of protection?
The answer lies in three main areas:
- Encrypt them – data encryption.
- Classify them into a given category – data labeling.
- Enforce protection rules on them – data loss prevention.
What are the unique benefits of combining DLP with a data classification system?
In this article, we will look at the unique benefits of combining points two and three – the opportunities created by combining a DLP (Data Loss Prevention) leak protection system with a data classification system.
Let’s start with the fact that these two present two completely different approaches to data classification:
- Data classification in the DLP (Data Loss Prevention) – system performs the detection of sensitive data through parameter-based (personal data, credit cards, self-defined rules) scanning and then implementing policies based on the search results. It is the IT department, with the support of the business, that centrally determines what we consider sensitive data and how we treat it. As the responsibility for digital data rests with the IT security department, the DLP system is the only tool for proactive policy implementation. For example, “if the file contains personal data and is to be sent outside the corporate network – get the manager’s confirmation.”
- Classification in Data Labeling systems assumes that the user knows what data he is working with and classifies it accordingly using the available “tag” – eg “Public” or “Private”. Here, the employee is a support for the IT department – he actively participates in the data classification process, which helps to reduce the number of false-positives and at the same time increases the awareness of working with data. For example, “if I am working on an important corporate project, I classify files related to it as” secret “. Remember that Data Labeling systems allow you to “tag” data but do not use remediation actions such as: notification, blocking.
Why is data owner awareness so important?
The above differences mean that the use of only one approach to determine what we consider crucial data for the company, exposes us to omission or incorrect classification of files. This will generate more false-positives or directly expose us to legal liability.
Classification errors exist mainly due to complicated internal connections (usually unstructured data) and high subjectivity – what is “public” to employee might be “secret” to company and vice versa. Data owner awareness is crucial here.
How to classify data with use of DLP system?
Let’s start with data classification process performed by DLP system – after all, it is responsible for performing a specific action (e.g. blocking) when it detects an illegal operation on specific data. Below we present what it looks
like:

To classify data, DLP systems have built-in classifiers:
- dictionaries / keywords – searches based on comparison of strings;
- regular expressions – regex – make it possible to match the classifier to the type of data, but remember that a “narrow” regex (too narrowly defined) will catch everything;
- scripts – these are regexes plus a validating algorithm, e.g. not every 11 digits is a PESEL number;
- machine learning – the system “learns” from the test data and then detects documents with a certain probability for the test sequence, here the key lies in choosing the right test data,
- fingerprinting – a magnum of DLP systems – we create “hashes” of sensitive data, e.g. fragments of a commercial contract, and use them to compare with data detected elsewhere; resistant to file structure changes, detect unstructured data.
But what if the system misses something?
Well… what if in our pile of documents (and it is difficult to meet someone who would have full control over the documents created and managed in the organization) the system qualifies something in a wrong way or does not qualify at all? Data labeling helps here – allowing the user to classify the document he is working on himself. In short, it looks like this:
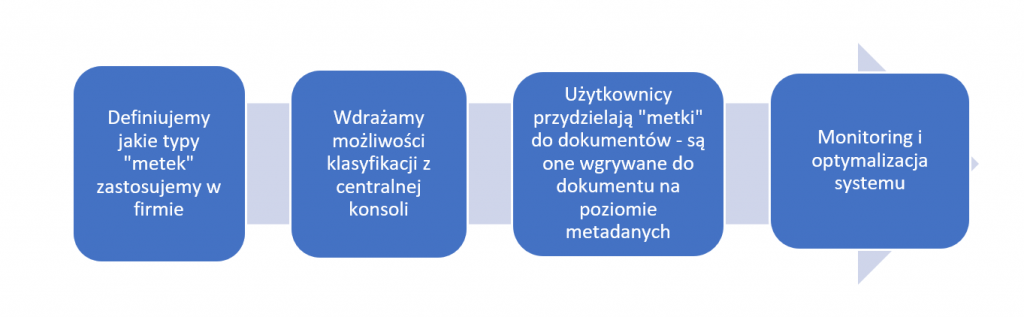
Thought is simple – the author of the document will be the best source of information on how to classify it.
We wrote earlier that using only one approach (and therefore the system) creates room for error.
So what are the benefits of integrating DLP and Data Labeling?
- Complete and Accurate Classification – By adding a data labeling policy to a DLP system, the file is classified twice: by the IT department and by the user. This helps: classify files that one of the parties skipped (the DLP system classifies the data without a “tag”, and the user can add a “tag” to a file that DLP skips).
- Double validation – what if the DLP system caught customer data in the file and the employee identified the file as “Public” and tried to send it by e-mail outside the organization? By using both systems, security analysts can control such cases and resolve inaccuracies.
- Reduction of false-positives – results from double validation, but it is so important that it deserves a separate point. During the operation of the system in the organization, thanks to double validation, we can significantly improve the work of our analysts. Can you imagine efficiently handling 5000 alerts a day?

The integration of Data Labeling and DLP systems is the next step in data protection, allowing users to engage in a culture of working with data and support security teams. In addition to additional layer of data protection, we support the development of awareness and good practices for working with data in the organization. We strongly recommend combining the two worlds – security teams and data users – the results may surprise you.


