
Dlaczego warto jest połączyć system ochrony przed wyciekiem typu DLP z systemem klasyfikacji danych
GDPR, PCI DSS, dyrektywa NIS… Ze względu na postępującą cyfryzację, organizacje i Państwa wymagają coraz to nowych standardów ochrony użytkownika w cyberprzestrzeni. Wraz ze wzrostem ograniczeń dotyczących przechowywania i przetwarzania danych wrażliwych, rośnie również zainteresowanie oprogramowaniem do ich klasyfikacji i ochrony. Praktycznie każdy pracownik generuje dane wrażliwe – pracując z danymi osobowymi (sprzedaż, HR), danymi finansowymi (księgowość, finanse) czy danymi stanowiącymi o przewadze konkurencyjnej (cenniki, projekty). Dane te są przetwarzane na wiele sposobów: kopiowane, wycinane, restrukturyzowane, parafrazowane, sklejane…
Znacznie komplikuje to proces ich ochrony. Stosunkowo łatwo jest chronić dane ustrukturyzowane w tabeli czy dokumencie o znanym układzie. Z kolei gorzej jeżeli są to dane nieustrukturyzowane – niestandardowe umowy, memoranda czy fragmenty e-maili.
Nasuwa się pytanie – co możemy zrobić z danymi w kontekście ich ochrony?
Odpowiedź zawiera się w trzech głównych obszarach:
- Zaszyfrować je – Data Encryption.
- Zaklasyfikować je do danej kategorii – Data Labelling.
- Nałożyć na nie reguły ochrony – Data Loss Prevention.
Jakie są unikalne korzyści z połączenia DLP z systemem klasyfikacji danych?
W tym artykule zajmiemy się unikalnymi korzyściami wynikającymi z połączenia punktów drugiego i trzeciego – czyli możliwościami jakie stwarza połączenie systemu ochrony przed wyciekiem typu DLP (Data Loss Prevention) z systemem klasyfikacji danych.
Zacznijmy od tego, że prezentują one dwa zupełnie odmienne podejścia do klasyfikacji danych:
- Klasyfikacja danych w systemie DLP (Data Loss Prevention) zakłada wykrycie danych wrażliwych poprzez oparte na parametrach (dane osobowe, karty kredytowe, samodzielnie ustalone reguły) skanowanie zasobów a następnie wdrożenie na nich polityk w oparciu o wyniki wyszukiwania. To dział IT, przy wsparciu biznesu, centralnie ustala co uważamy za dane wrażliwe i jak je traktujemy. Jako, że odpowiedzialność za dane cyfrowe spoczywa na dziale bezpieczeństwa IT – system DLP to jedyne narzędzie aktywnego wdrażania zasad. Przykładowo „jeżeli plik zawiera dane osobowe i ma być wysłany na zewnątrz sieci firmowej – uzyskaj potwierdzenie menadżera”.
- Klasyfikacja w systemach typu Data Labelling zakłada, że to użytkownik wie z jakim danymi pracuje i odpowiednio je zaklasyfikuje za pomocą dostępnej „metki” – np. „Public” czy „Private”. Tutaj pracownik jest niejako wsparciem dla działu IT – aktywnie uczestniczy w procesie klasyfikacji danych co pomaga zmniejszyć liczbę false-positives i jednocześnie zwiększa świadomość pracy z danymi. Przykładowo „jeżeli pracuję nad ważnym firmowym projektem, pliki z nim związane klasyfikuję jako „tajne”. Pamiętajmy, że systemy Data Labelling pozwalają „metkować” dane ale nie stosują akcji remediacyjnych typu: powiadomienie, blokowanie.
Dlaczego tak ważna jest świadomość właściciela danych?
Powyższe różnice sprawiają, że zastosowanie tylko jednego podejścia do określania co uważamy za dane kluczowe dla firmy, naraża nas na pominięcie bądź niewłaściwe zaklasyfikowane plików. Wygeneruje to więcej false-positives lub narazi nas wprost na odpowiedzialność prawną.
Błędy w zakresie klasyfikacji istnieją głównie za względu na skomplikowane powiązania wewnętrzne (najczęściej danych nieustrukturyzowanych) i na duży subiektywizm – to co dla mnie jest „publiczne” dla firmy może być „tajne” i na odwrót. Świadomość właściciela danych jest tu kluczowa.
Jak klasyfikować dane poprzez DLP?
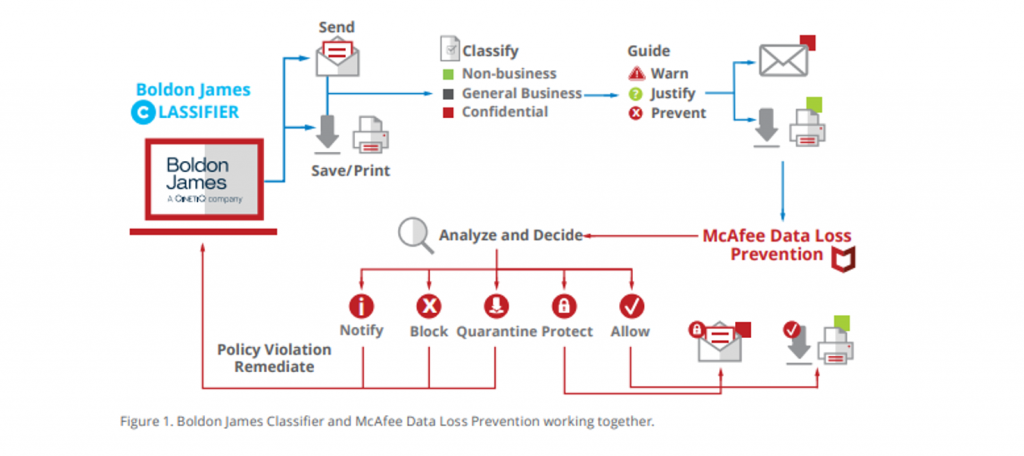
Zacznijmy od klasyfikacji danych poprzez system DLP – to w końcu on jest odpowiedzialny za wykonanie określonej akcji (np. blokowania) gdy wykryje niedozwoloną operację na określonych danych.
Poniżej prezentujemy jak to wygląda:

Aby sklasyfikować dane, systemy DLP mają wbudowane mechanizmy:
- słowniki/słowa kluczowe – wyszukiwania na podstawie porównania ciągów znaków,
- wyrażenia regularne – regex – dają możliwość dużego dopasowania klasyfikatora do rodzaju danych, jednak pamiętajmy za „wąski” regex (za wąsko zdefiniowany) wyłapie wszystko,
- skrypty – są to regex-y plus algorytm walidujący np. nie każde 11 cyfr to PESEL,
- machine learning – system „uczy się” na podstawie danych testowych i potem wykrywa dokumenty z określonym prawdopodobieństwem do ciągu testowego, czyli wszystko zależy od danych testowych,
- fingerprinting– magnum systemów DLP – tworzymy „hashe” danych wrażliwych np. fragmentów umowy handlowej i używamy ich do porównania z wykrytymi gdzie indziej danymi; odporne na zmiany struktury plików, wykrywają dane nieustrukturyzowane.
Ale co jeśli system coś pominie?
No właśnie, a co jeżeli w naszej dżungli dokumentów (a ciężko jest spotkać kogoś kto by w pełni panował nad dokumentami tworzonymi i zarządzanymi w organizacji) system coś źle zakwalifikuje albo nie zakwalifikuje? Tutaj pomaga data labelling – który pozwala użytkownikowi samodzielnie zaklasyfikować dokument, nad którym pracuje.
W skrócie wygląda to tak:
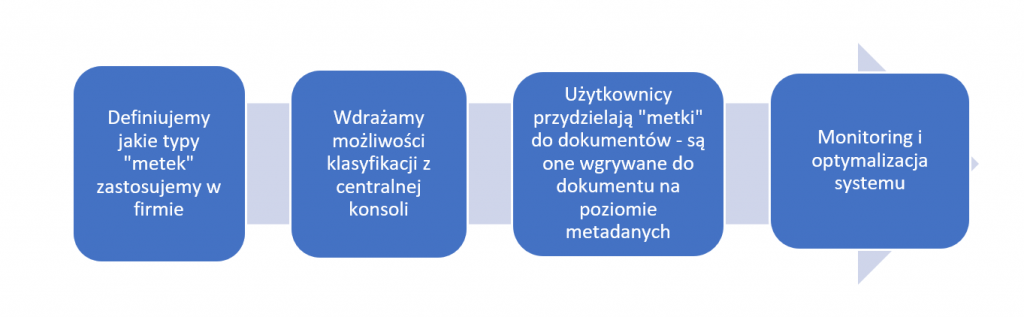
Założenie jest proste – autor dokumentu będzie najlepszym źródłem informacji o tym jak go zaklasyfikować.
Pisaliśmy wcześniej, że wykorzystanie tylko jednego podejścia (a co za tym idzie – systemu) stwarza przestrzeń na błędy.
Jakie są zatem korzyści z integracji systemu DLP i Data Labelling?
- Całościowa i dokładna klasyfikacja – dodając do systemu DLP politykę opartą na „metce” przydzielonej w ramach data labellingu plik jest klasyfikowany podwójnie: przez dział IT i przez użytkownika. Pomaga to: klasyfikować pliki pominięte przez jedną ze stron (system DLP zaklasyfikuje dane bez „metki”, natomiast użytkownik może dodać „metkę” do pliku pominiętego przez DLP).
- Podwójna walidacja – co jeżeli system DLP wyłapał w pliku dane klienta, a pracownik określił plik jako „Publiczny” i próbował wysłać go mailem na zewnątrz organizacji? Dzięki zastosowaniu obu systemów, analitycy bezpieczeństwa mogą kontrolować takie przypadki i wyjaśniać nieścisłości.
- Redukcja false-positives – wynika z podwójnej walidacji, jednak jest na tyle istotna że zasługuje na oddzielny punkt. W trakcie działania systemu w organizacji, dzięki podwójnej walidacji możemy znacznie ułatwić pracę naszym analitykom. Wyobrażacie sobie sprawne obsłużenie 5000 alertów dziennie?
Chcesz poszerzyć swoją wiedzę na temat klasyfikacji danych? Zapraszamy do zapoznania się z ulotką w zakładce Rozwiązania


