
KLASYFIKACJA DANYCH: PRZYPADEK UŻYCIA – OGRANICZENIE RYZYKA
System klasyfikacji danych ogranicza ryzyko wprowadzając widoczność w zakresie kategorii informacji i włączając użytkowników w proces kategoryzowania informacji. To w efekcie czyni ich współodpowiedzialnymi za proces ochrony danych. Dlaczego warto klasyfikować dane przeczytasz w poniższym tekście.
W artykule poświęconym klasyfikacji danych, zdefiniowaliśmy jej główny cel. Jest nim wychwycenie kilku procent krytycznych danych wśród organizacyjnego „szumu” i zapewnienie ich widoczności.
W poniższym artykule skupimy się na jednym z głównych obszarów, które Gartner identyfikuje jako „obszary przydatności” systemów do klasyfikacji plików.
Artykuł może być szczególnie przydatny w fazie przedwdrożeniowej, aby określić w jakim stopniu oprogramowanie spełnia założenia programu ochrony danych.
W swoim przewodniku rynkowym dotyczącym File Analysis Software (do którego włączają się systemy do klasyfikacji danych), firma Gartner wymienia cztery ogólne obszary przydatności tego oprogramowania.
Pierwszym z nich jest OGRANICZENIE RYZYKA, krótko scharakteryzowane w poniższych punktach:
- Ogranicza dostęp do informacji zawierających dane osobowe (PII).
- Pozwala kontrolować lokalizację i dostęp do własności intelektualnej (IP).
- Zmniejsza obszar ataku na dane wrażliwe.
- Pozwala dodać dodatkowy parametr egzekucji reguł w innych programach np. DLP.
Na potrzeby różnorodnych analiz wymagań omówimy powyższe punkty oraz proponujemy, w jaki sposób je zastosować.
Ograniczenie dostępu do informacji zawierających dane osobowe
Dane osobowe (PII) to dane, które można wykorzystać do zidentyfikowania, skontaktowania się lub zlokalizowania konkretnej osoby lub odróżnienia jednej osoby od drugiej.
Informacje umożliwiające identyfikację są często definiowane jako imię lub inicjał imienia i nazwiska osoby w połączeniu z co najmniej jednym z następujących numerów:
- ubezpieczenia społecznego
- prawa jazdy
- dowodu osobistego lub paszportu
- karty kredytowej
- konta finansowego w połączeniu z kodem zabezpieczającym, kodem dostępu lub hasłem, które umożliwiałyby dostęp do konta Informacje medyczne lub dotyczące ubezpieczenia zdrowotnego.
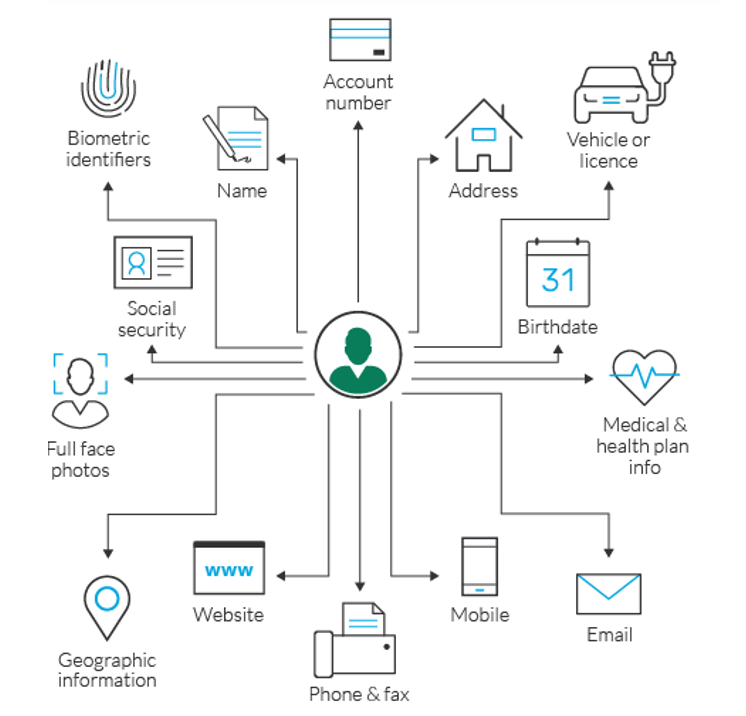
Źródło: Imperva
Przy stosowaniu mechanizmów klasyfikacji zwykle bazujemy jednak na innym poziomie „etykietowania” – np. „Poufne”, „Wewnętrzne”, „Publiczne”. Gdybyśmy każdy dokument zawierający dane osobowe klasyfikowali jako „poufny” – liczba poufnych dokumentów w organizacji szybko wykroczyłaby poza jakiekolwiek ramy kontroli.
Dlatego kluczowe zadanie polega na określeniu w jakich kategoriach informacji (które zastosujesz w swoim projekcie) znajdą się dane osobowe i w jaki sposób to uwzględnić.
- Subiektywne określenie „grup” danych osobowych – według orientacyjnego poziomu wrażliwości.
- Poziom poufności, jakiego wymagają konkretne grupy danych osobowych.
- Potencjalny wpływ, jaki naruszenie danych osobowych lub uszkodzenie danych miałoby na zaangażowane osoby.
- Znaczenie dostępności tych danych.
Może okazać się, że niektóre informacje zmienią swoją kategorią tylko dlatego, że plik zawiera dane osobowe.
Tutaj warto nadmienić, że wiodące rozwiązania do klasyfikacji danych pozwalają ustalić „podkategorie”, które precyzują kategorie ogólne np. POUFNE DANE OSOBOWE. Wszelkie postanowienia dotyczące kategoryzacji plików zawierających dane osobowe muszą zostać odzwierciedlone w odpowiedniej polityce bezpieczeństwa.
Obejrzyj także:
Kontrola lokalizacji i dostępu do własności intelektualnej (Intelectual Property – IP)
Zwykle dzieje się to poprzez integrację z systemem klasy DRM – Digital Rights Management.
Systemy klasyfikacji same w sobie zapewniają możliwość przeprowadzenia tzw. discovery – określenia jakie informacje (z objętych kategoryzacją) znajdują się w wewnątrz pliku, jednak na dość wysokim poziomie ogólności. Aby zapewnić sobie możliwość zaawansowanego kategoryzowanie plików na podstawie zawartość (z centralnej konsoli) – warto pomyśleć nad integracją z systemem DLP – Data Loss Prevention.
System klasyfikacji danych usprawnia działania DLP i DRM, ponieważ pozwala im „widzieć” jak twórca zaklasyfikował dany plik (lub jak plik zaklasyfikował automatycznie sam program).
Zmniejszenie obszaru ataku na dane wrażliwe
Systemy klasyfikacji danych wspierają ochronę danych w 3 obszarach:
- Inwentaryzacja danych – pozwalają określić, gdzie znajdują się dane oznaczone w poszczególnych kategoriach, ile ich jest i z jakich rodzajów się składają.
- Świadomość użytkownika – użytkownicy świadomie kategoryzujący dane automatycznie staranniej się z nimi obchodzą, co poprawia ogólny poziom bezpieczeństwa.
- Ochrona danych – klasyfikator to techniczne przedłużenie organizacyjnych polityk bezpieczeństwa informacji. Pozwala zarówno kategoryzować pliki w myśl etykiet opisanych w procedurach, jak i wyzwalać odpowiednie reguły w innych rozwiązaniach bezpieczeństwa IT (o tym w punkcie 4).
Możliwość dodania dodatkowego parametru egzekucji reguł w innych programach
Dotyczy integracji klasyfikatora danych z technologiami takimi jak:
- Data Loss Prevention
- Digital Rights Management
- Identity&Access Management
- File Encryption
Zbiór plików przyporządkowanych do danej „etykiety” widziany jest przez każde z powyższych rozwiązań jako „grupa” na którą można nałożyć odpowiednie polityki bezpieczeństwa. Warto dodać, że integracja z powyższymi to jeden z ważniejszych paramterów podczas rozpatrywania zakupu rozwiązania do klasyfikacji danych.
Jak widzimy z analizy powyższych obszarów – system klasyfikacji danych ogranicza ryzyko poprzez wprowadzenie widoczności w zakresie kategorii informacji i włączenie użytkowników w proces kategoryzowania informacji co w efekcie czyni ich współodpowiedzialnymi za proces ochrony danych.
Firmy przyjmują różne miary ograniczania ryzyka:
- procentową redukcję nieautoryzowanych miejsc przechowywania danych,
- liczbę incydentów dotyczących poszczególnych kategorii danych per miesiąc (tutaj bez klasyfikatora ciężko wogóle mówić o kategoriach),
procentową redukcję false-positives z innych rozwiązań np. DLP przez wprowadzenie polityk opartych o dane z klasyfikatora.
Co ciekawe po wdrożeniu, firmy zyskują poprawę w każdym z nich. W kolejnym artykule poruszymy tematykę wsparcia zgodności z regulacjami.


